
Aprendizaje de Máquina Vectorial (VML) de Symantec

El Desafío Ciego: Proteger los Datos No Estructurados en Ciberseguridad México
En el complejo ecosistema de la ciberseguridad en México, la información sensible ya no reside únicamente en campos definidos de una base de datos. Hoy, una amplia gama de datos confidenciales y propiedad intelectual fluye a través de volúmenes de datos no estructurados. Estos incluyen el lenguaje humano en correos electrónicos, documentos, código fuente, PDF y archivos de imagen, constituyendo cerca del 80% del total de datos empresariales. Identificar y proteger estos tipos de datos es un desafío enorme, y los sistemas de DLP (Data Loss Prevention) tradicionales, basados en métodos rígidos como expresiones regulares, a menudo generan un exceso de falsas alertas o, peor aún, fallan en la Detección de Datos No Estructurados críticos.
Para hacer frente a las amenazas de fuga de información y proteger la reputación corporativa, las empresas necesitan un enfoque de Clasificación de contenido que sea inteligente y adaptable. Symantec Data Loss Prevention (DLP), a través de su tecnología patentada Aprendizaje de Máquina Vectorial (VML), ofrece una solución que va más allá de los métodos rígidos, utilizando el Aprendizaje automático supervisado para comprender la naturaleza y la intención del dato en lugar de solo su patrón. Esta tecnología permite a las empresas tomar decisiones de seguridad automatizadas basadas en el contexto, algo esencial en un entorno donde los dispositivos móviles y las redes sociales son canales constantes de comunicación.
🧠 Aprendizaje Automático Supervisado: La Ingeniería Detrás de VML

El Aprendizaje de Máquina Vectorial (VML) es la tecnología de Symantec ciberseguridad que permite a las organizaciones crear políticas altamente precisas para proteger los datos confidenciales que, por su naturaleza, son difíciles de describir con métodos convencionales. Su capacidad de procesar grandes volúmenes de datos y tipos de datos no estructurados es lo que lo diferencia de otras soluciones de DLP.
¿Cómo funciona el Aprendizaje de Máquina Vectorial?
VML se basa en el algoritmo de Support Vector Machine (SVM), un método clásico y robusto de aprendizaje automático supervisado. Este algoritmo busca el hiperplano óptimo que mejor separa los puntos de datos de una clase de otra en un espacio multidimensional:
Entrenamiento y Muestras de Alto Valor: VML se entrena utilizando un conjunto de documentos de ejemplo proporcionados por la organización. El administrador debe entrenar modelos de la siguiente manera:
Ejemplos Positivos: Documentos que deben protegerse (ej., código fuente propietario, contratos legales). Estos son los datos confidenciales que el sistema debe buscar.
Ejemplos Negativos: Documentos que no deben protegerse (ej., código abierto, manuales de usuario que pueden circular libremente). Estos ejemplos enseñan al modelo a reducir los falsos positivos.
Creación del Perfil y PLN: El algoritmo utiliza técnicas de Procesamiento de Lenguaje Natural (PLN) para analizar estos documentos. PLN se emplea comúnmente en la Clasificación de texto en conjuntos de datos de alta dimensión, transformando el lenguaje humano en vectores numéricos (de ahí el nombre "Vectorial") que definen la esencia y la intención del contenido. Este paso permite a los algoritmos de machine learning entender la semántica, no solo las palabras clave.
Detección por Similitud: El perfil resultante se utiliza en la política DLP. Cuando VML analiza un contenido en la red, determina si ese contenido es similar a los documentos del conjunto de entrenamiento positivo, con un alto grado de precisión.
Este enfoque de aprendizaje automático supervisado añade una tercera dimensión a la detección DLP, complementando las técnicas tradicionales de "descripción" y "huella digital", lo que reduce drásticamente las falsas alarmas y la carga operativa. Permite a las empresas tomar decisiones de política de seguridad más efectivas.
🛡️ Análisis de Datos y Aplicaciones Críticas de VML
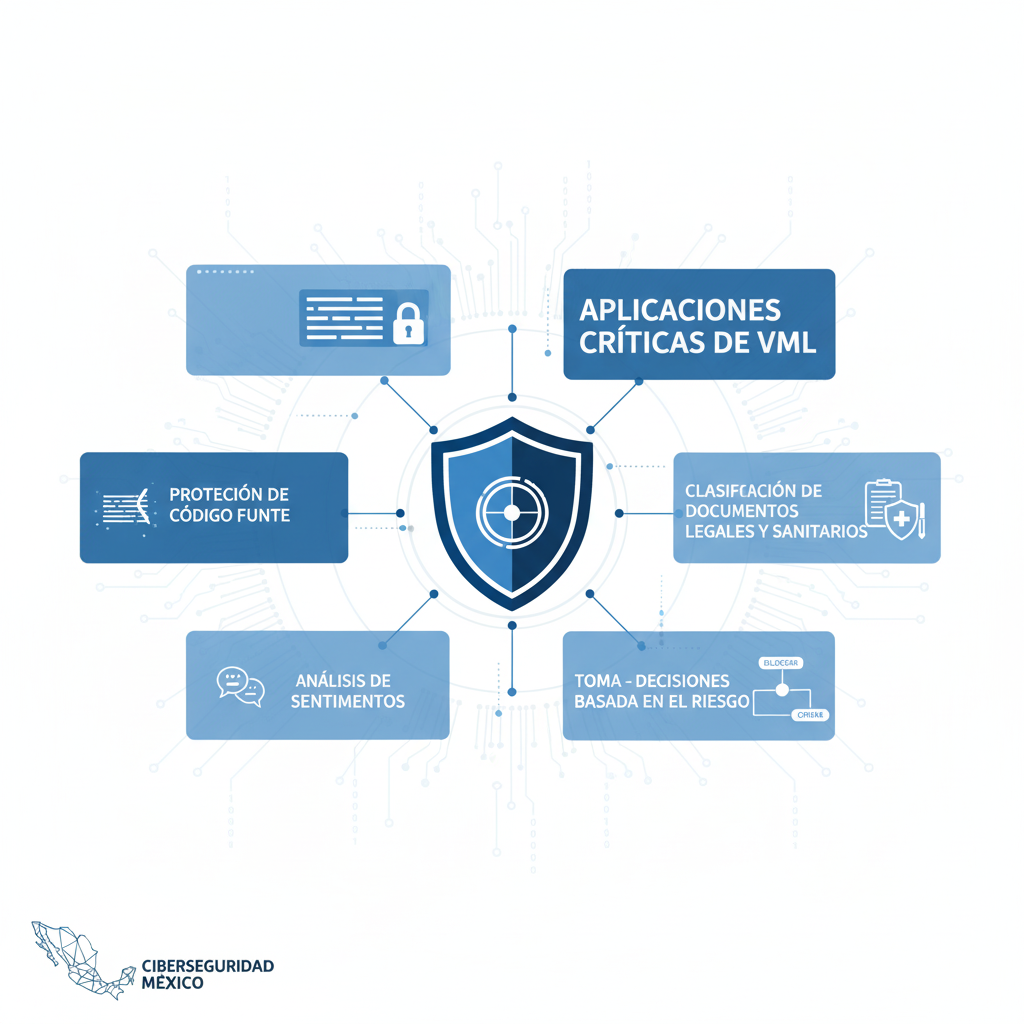
El Aprendizaje de Máquina Vectorial es esencialmente una herramienta avanzada de análisis de datos para la seguridad, crítica para la ciberseguridad en México en el entorno actual. Su capacidad para entrenar modelos y analizar tipos de datos complejos lo hace indispensable:
Protección de Código Fuente Patentado: Un caso de uso principal es proteger los datos confidenciales como el código fuente propietario de un desarrollador para que no salga de la organización (vía email o USB), mientras que se permite la libre circulación del código abierto.
Clasificación de Documentos Legales y Sanitarios: VML es superior para identificar documentos que son estructuralmente similares, como formularios de reclamación de seguros, documentos de I+D o informes de mercado, cuya forma puede variar, pero cuya naturaleza confidencial permanece constante. Este nivel de Clasificación de contenido es vital para el cumplimiento normativo.
Análisis de Sentimientos y Comportamiento: El uso del Procesamiento de Lenguaje Natural inherente al VML, combinado con otras herramientas de la plataforma Symantec, permite realizar análisis de sentimientos sobre comunicaciones, identificando patrones de frustración o intención maliciosa antes de que se produzca una fuga.
Toma de Decisiones Basada en el Riesgo: Los resultados del análisis de datos de VML se alimentan al motor de políticas de Symantec. Esto permite permitir a las empresas tomar decisiones automatizadas: cifrar, bloquear o alertar en función del nivel de riesgo detectado, no solo de una coincidencia de patrón.
Integración de Tecnologías para Volúmenes de Datos Masivos
Para lograr una ciberseguridad en México total, Symantec DLP integra VML con otras capacidades avanzadas para manejar la amplia gama de tipos de datos y volúmenes de datos:
Reconocimiento Óptico de Caracteres (OCR): Extrae y analiza texto incrustado en imágenes, capturas de pantalla y documentos escaneados, asegurando que la información sensible oculta en formatos gráficos también sea detectada.
Análisis de Comportamiento de Usuario (UEBA): Utiliza machine learning para establecer una línea base de actividad normal, alertando sobre comportamientos riesgosos o amenazas internas basándose en una evaluación de riesgo comparativa.
Cobertura de Canales: La solución monitoriza el tráfico a través de una amplia gama de canales, incluyendo web, correo electrónico, redes sociales, y dispositivos móviles, asegurando que los datos confidenciales nunca salgan sin control.
⭐ El Impacto de la IA en la Toma de Decisiones y el Cumplimiento Normativo
La implementación de VML por parte de Symantec ciberseguridad es un ejemplo claro de cómo la inteligencia artificial aplicada transforma la toma de decisiones y la gestión del riesgo.
Antes, la Clasificación de contenido requería una supervisión humana constante de los volúmenes de datos, gastando tiempo valioso en falsos positivos. Ahora, los algoritmos de machine learning asumen la carga, permitiendo a los equipos de seguridad analizar datos y centrarse únicamente en incidentes de alto riesgo. Esto se traduce directamente en un mejor cumplimiento normativo, ya que la IA proporciona la evidencia de que las políticas de proteger los datos confidenciales se aplican de manera consistente y auditable.
La capacidad de permitir a las empresas tomar decisiones rápidas y precisas sobre la cuarentena o el bloqueo de datos que se asemejan al código fuente es un cambio de juego para la ciberseguridad en México, donde la protección de la propiedad intelectual es primordial. Este enfoque proactivo de análisis de datos basado en el lenguaje humano y el contexto es el futuro de la protección de datos confidenciales.
Conclusión: La Inteligencia como Defensa Final

El camino hacia una ciberseguridad en México robusta pasa inevitablemente por dominar la Detección de Datos No Estructurados. El Aprendizaje de Máquina Vectorial (VML) de Symantec es la respuesta inteligente a este desafío, transformando los vastos datos de la empresa en una defensa activa.
Al emplear el Aprendizaje automático supervisado y el Procesamiento de Lenguaje Natural, su organización puede implementar una Clasificación de contenido con una precisión sin precedentes. Esta tecnología no solo minimiza los falsos positivos, sino que eleva la protección de datos a un nivel donde la IA trabaja para identificar y proteger los datos confidenciales más complejos y valiosos de su negocio. Es la única forma efectiva de gestionar la amplia gama de tipos de datos y volúmenes de datos que fluyen a través de dispositivos móviles y redes sociales, asegurando el cumplimiento normativo y mejorando la toma de decisiones.
¿Listo para implementar la Clasificación de contenido impulsada por VML? Descubra cómo Symantec Data Loss Prevention puede blindar sus Datos No Estructurados y permitir a las empresas tomar el control total. Agenda una consultoría gratuita con nuestros expertos de OXM Tech.